MPC Primitives
概要
この記事では Massively Parallel Algorithm (MPC) モデルにおける Join アルゴリズムで利用される基礎的なアルゴリズムについてまとめます。
基礎的なアルゴリズム
この章で紹介するすべてのアルゴリズムは、入力サイズを $N$ 、サーバーの台数を $p$ とすると、最大通信量 $O(N / p)$ で解くことができます。 さらに、$N > p^{1 + \epsilon}$($\epsilon > 0$) を満たす場合は、$O(1)$ ラウンドで解くことができます。
Prefix sum
Prefix sum とは、入力としてサイズ $N$ の配列 $A = a_0, a_1, \dots, a_N$ が与えられたとき、各 $i$ について、$b_i = \sum_{j = 0}^i a_i$ を計算する問題です。 実際には演算子は結合法則を満たすものであれば和でなくとも構いません。
この問題を解く MPC アルゴリズムでは、根付き木 $\mathcal{T}$ を構築します。 $\mathcal{T}$ は $N$ 個の葉を持ち、葉以外のノードは $d = M$ 個の子を持つように構築します。 したがって $\mathcal{T}$ の高さ $L$ は $\lceil \log_d N \rceil = O(\log_M N)$ となります。 ここで $M$ は最大通信量の上界を表すパラメーターです。 木の各階層に対してレベルを定義します。 根のレベルは $0$ で、葉のレベルは $L - 1$ です。 あるレベル $l$ の$k$ 番目のノードを $(l, k)$と表記します。 こうすると、$(l, k)$ の親と子は以下のように計算することができます。
- 親: $p(v) = (l - 1, \lfloor k / d \rfloor)$
- $j$ 番目の子($j$ は0-indexed): $w_j = (l + 1, k \cdot d + j)$
アルゴリズムの最初のステップで、各入力 $a_i$ は葉ノード $v = (L - 1, i)$ に送られます。 その後、$\mathcal{T}$ 上でボトムアップの計算とトップダウンの計算を行うことで prefix sum を計算します。
ボトムアップの計算では、レベル $L - 1$ から根に向かって計算を行います。 レベル $L - 1$ では、各ノード $v$ は、$p(v)$ に割り当てられた入力 $a_i$ を送信します。 レベル $0 < l \le L - 1$ では、各ノード $v$ は、子から送られてきたデータの和を計算し、$p(v)$ に送信します。 具体的には、各子ノード $w_0, w_1, \dots, w_{d - 1}$ から送られてきたデータをそれぞれ $s_{w_j}$ とすると、$s_v = \sum_{j = 0}^{d - 1} s_{w_j}$ を送信します。
トップダウンの計算では、ボトムアップの計算とは反対に、根からレベル $L - 1$ に向かって計算を行います。 根では、各子ノード $w_i (0 \le i \le d - 1)$ に対して $s^\prime_i = \sum_{j = 0}^{i - 1} s_{w_j}$ を計算して送信します($w_0$ に対しては$0$が送られます)。 レベル $1 \le l < L - 1$ では、各子ノード $w_i (0 \le i \le d - 1)$ に対して、親ノードから受け取った $s_{p(v)}$ と $\sum_{j = 0}^{i - 1} s_{w_j}$ の和を計算し送信します($W_0$ に対しては$s_{p(v)}$ が送られます)。 レベル $L - 1$ では、各ノード $v$ は、親ノードから受け取った $s_{p(v)}$ と入力 $a_i$ の和を計算します。 これが、求めたかった $b_i = \sum_{j = 0}^i a_i$ となっています。
このアルゴリズムは、$O(\log_M N)$ のラウンドを必要とします。 しかし、$M = N / p$ かつ、$N > p^{1 + \epsilon} (\epsilon > 0)$ とすると、$O(1)$ ラウンドで計算が完了します。 $$ \begin{align*} \log_M N &= \log_{N/p} N \\ &= \frac{\log N}{\log N/p} \\ &= \frac{\log N}{\log N - \log p} \\ &= O(\frac{\log N}{\log N - \log N / (1 + \epsilon)}) \\ &= O(1) \end{align*} $$ 4行目の式変形は $\log N > \log p^{1 + \epsilon}$を利用しています。 このアルゴリズムの最大通信量も確認します。 まず最初のステップで発生する通信量ですが、各サーバーに均等に葉ノードを割り振ると $N / p$ となります。 次に、ボトムアップの計算で発生する通信量です。 各レベルのノードは、高々 $M$ 個の子からメッセージを受け取ります。 最もノード数が多い、レベル $1$ でもノード数は $N / M = p$ であるため、重複なくサーバーにノードを割り振ることができます。 したがって、各サーバーが受け取るデータも高々 $N / p$ 個となります。 最後に、トップダウンの計算で発生する通信量です。 トップダウンの計算では、各ノードは $1$ 個のメッセージしか受け取りません。 $1$ サーバーあたりのノードが最も多くなる最終ラウンドでも、$1$ サーバーあたりのノード数は上述の通り $N / p$ であるため、トップダウンの計算でも各サーバーが受け取るデータ数は高々 $N / p$ となります。 以上より、$M = N / p$ かつ、$N > p^{1 + \epsilon} (\epsilon > 0)$ の場合の prefix sum の最大通信量は $O(N / p)$ となります。
設定をシンプルにするために $d = 2$ として、実際にアルゴリズムを動かしてみます。
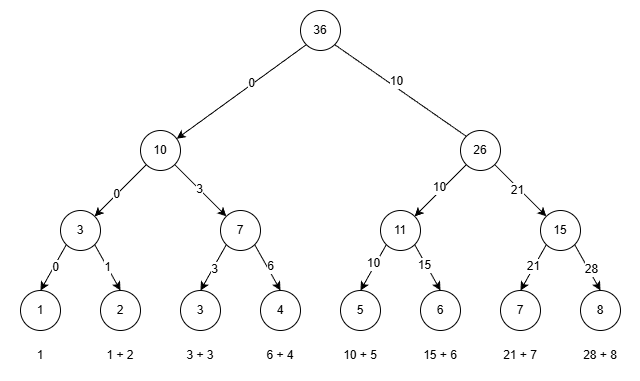
入力を $A = 1, 2, 3, 4, 5, 6, 7, 8$ とします。
初期データの配置が完了すると、$\mathcal{T}$ の状態は以下のようになります。
この状態でボトムアップの計算を行うと、$\mathcal{T}$ の状態は以下のようになります。
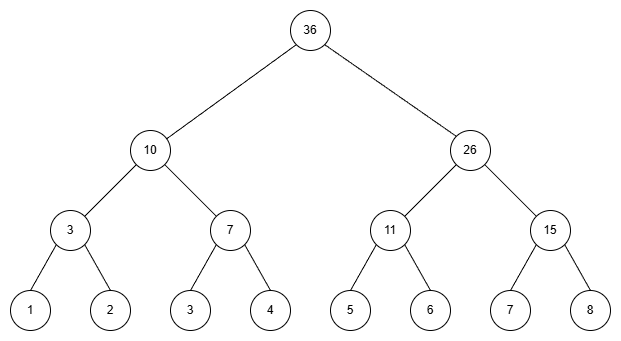
最後にトップダウンの計算を行うと、$\mathcal{T}$ の状態は下記のようになり、各 $b_i$ が正しく葉で計算されていることが分かります。
Multi-numbering
multi-numbering とは、入力として key-value ペアのリストが与えられたとき、このリストで同じキーを持つペアに対して $1, 2, 3, \dots$ のように連続する値を割り振る問題です。 この問題は、prefix sum を応用して解くことができます。 最初に、リストをキーでソートします。 MPC モデルは BSP モデルのアルゴリズムをエミュレートすることが可能であるため、BSP モデルのソートアルゴリズムを利用することができます。 これによって、最大通信量 $O(N / p)$ かつ定数ラウンドでソートを行うことができます。 ソートが完了したら、各ペアごとに Prefix sum の入力とするタプル $(x, y)$ を生成します。 具体的には、あるキーがソート済みのリストにおいて初めて現れる場合は $(0, 1)$ を、その他の場合は $(1, 1)$ を生成します。 このとき、サーバーをまたいで存在するキーについては、各サーバーだけではそのキーが初めて現れたのか判断することができません。 この問題は、各サーバーが次のサーバーに対して自身が持っている最も大きなキーを送信することで解決することができます。 ここで発生する通信量は $O(1)$ であるため、最大通信量には影響しません。
次に、生成したタプルに対してprefix sum を計算します。 prefix sum は前述の通り結合法則を満たす演算子であれば計算することが可能です。 今回は、下記の演算子を用います。 $$ \begin{align*} (x_1, y_1)\oplus(x_2, y_2) = (x_1 x_2, y) \end{align*} $$ $y$ は以下のように計算します。 $$ \begin{equation} y = \begin{cases} y_1 + y_2 & \text{if } x_2 = 1; \\ y_2 & \text{if } x_2 = 0; \end{cases} \end{equation} $$ これによって、ソート済みの入力リスト内でキーが初めて現れたペアに対応するタプルでは $y$ が$1$となり、以降キーが変わるまでは連続した値を割り振ることができます。
入力されたキーを $2,5,1,3,4,2,4,1,5,4$ として実際にアルゴリズムを動かしてみます(Value は今回影響しないため省略)。 最初にキーをソートします。 $$ \begin{equation} 1,1,2,2,3,4,4,4,5,5 \end{equation} $$ 次に、prefix sum に入力するタプルを生成します。 $$ \begin{equation} (0,1),(1,1),(0,1),(1,1),(0,1),(0,1),(1,1),(1,1),(0,1),(1,1) \end{equation} $$ 最後に、prefix sum を計算します。 $$ \begin{equation} (0,1),(0,2),(0,1),(0,2),(0,1),(0,1),(0,2),(0,3),(0,1),(0,2) \end{equation} $$ 正しく multi-numbering が行えていることが確認できます。
Sum-by-key
sum-by-key は、入力としてキーとキーに紐づく重みのリストが与えられたときに、キーごとに重みの和を求める問題です。 この問題は multi-numbering と同様の考え方で解くことができます。 具体的には、multi-numbering では key-value ペアの value を考慮していませんでしたが、prefix sum の入力 $(x, y)$ を生成する際にvalue を $y$ とすることで、key ごとの重みの和を求めることができます。 prefix sum の計算が終わると、各キーの最後のタプル $(x, y)$ の$y$ に重みの和が格納されています。 ここでも、サーバーをまたぐキーについては追加の通信が必要となりますが、各サーバーが保持している最小のキーを前のサーバーに送信することで、自身がキーの重みの和を保持しているかどうかを判断することができます。
Multi-search
multi-search は、入力として $N_1$ 個の異なるキーと$N_2$ 個のクエリが与えられたとき、各クエリ $q$ について $q$ よりも小さい最も大きなキーを探索する問題です($N = N_1 + N_2$ とします)。 この問題も、prefix-sum を用いて解くことができます。 最初に、キーとクエリを合わせてソートします。 その後、prefix sum への入力 $A$ を以下のように生成します。
- キーの場合、キー自身を $a_i$ とする
- クエリの場合、$-\infty$を $a_i$ とする
演算子には max を利用します。 このような設定で prefix sum を計算すると、各クエリに対応する $b_i$ にはクエリよりも小さい最も大きなキーが格納されています。
Parallel-packing
parallel-packing は、入力として $N$ 個の実数 $x_1, x_2, \dots, x_N (0 < x_i \le 1)$ が与えられたとき、条件を満たすように $m$ 個の集合 $Y_1, Y_2, \dots, y_m$ に分割する問題です。 分割時の条件は以下のとおりです。
- 各 $1 \le j \le m$ について、$\sum_{i \in Y_j} x_i \le 1$
- 1つの $j$ を除いて、$\sum_{i \in Y_j} x_i \ge 1/2$
入力値は初期状態として各サーバーに分配されており、prallel-packing を解くアルゴリズムは、最終的に各 $x_i$ について所属する集合 $j$ を決定し $(i, j)$を出力する必要があります。
この問題も、prefix sum を用いて解くことができます。 最初に、各サーバー $i$ において貪欲にパッキングを行います。 これによって、2つの条件を満たした複数の集合と $\sum x_i \ge 1/2$ を満たすことができなかった1つの集合が作られます。 ここで、各サーバー $i$ において $g_i$ と $h_i$ を定義します。 $g_i$ は2つの条件を満たした集合の数です。 $h_i$ は $\sum x_i \ge 1/2$ を満たすことができなかった集合に含まれる実数の和です。 次に、$g_i$ に対して prefix sum を計算します。 これによって、各サーバーはローカルで作成した集合に対して id を振ることができます。 この段階で、ローカルで条件を満たすことができた集合については処理が完了します。 続いて、ローカルでは条件を満たすことができなかった集合の統合を行います。 そのために、アルゴリズムを再帰的に実行します。 具体的には、prefix sum のように葉以外のノードが子を $N / p$ 個持つような根付き木を構築し、各レベルで上記のアルゴリズムを実行します(集合の id は下位レベルの最後の id + 1 をスタートとします)。 そして、そのレベルで統合しきれなかった集合については、$h_i$ を親ノードに送信していきます。 この再帰処理では、問題のサイズがレベルが上がるたびに $p / N$ 倍されていくため、$O(\log_{N / p} p) = O(1)$ ラウンドでアルゴリズムは終了します。
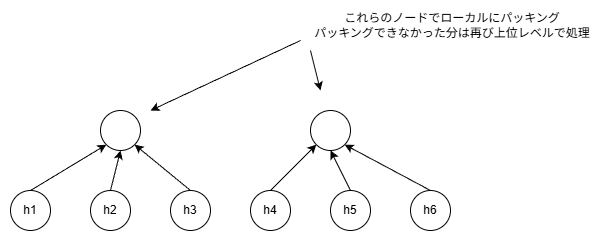
再帰処理のイメージ
応用
Semi-join
semi-join は共通する属性 $x$ を持つ2つのリレーション $R_1$ と $R_2$ が与えられたとき、$R_1$ のタプルのうち、同じ $x$ の値を持つタプルが $R_2$ に存在するタプルのみを取り出す処理です。 $R_1 \ltimes R_2$ と表記されます。 この処理は、join クエリを縮小させ最大通信量を低く保つためによく利用されます。 semi-join は、multi-search を用いて実現することができます。 具体的には、$R_1$ のタプルの $x$ の値をクエリとし、$R_2$ のタプルの $x$ の値をキーとして multi-search を実行します。 そして、$R_1$ のタプルのうち、multi-search の結果が自身の $x$ の値と等しいタプルだけを残します。 このようにmulti-search を応用することで、semi-join を実現することができます。
リレーションの分割
MPC モデルにおける join アルゴリズムではリレーションを細かく分割し並列に解くことがあります。 分割の際には、分割後のサブリレーションのサイズが一定のサイズ以下になっているようにします。 この操作は、multi-numbering と parallel-packing を応用することで実現可能です。 まず、multi-numbering を用いて、キーごとの出現頻度を求めます。 その後、所望のサブリレーションのサイズ $L$ で、出現頻度を割ります。 このとき、出現頻度が $L$ 以上のキーは、サブリレーションに含めることができないため除外します(このようなキーは heavy なキーと呼ばれ、通常その他のキーとは異なる処理をされます)。 最後に、残ったキーについて、parallel-packing を行うことで、サイズ $L$ 以下のサブリレーションに分割することができます。